
LA VIDEO NUMERIQUE

Techniques de codage et décodage (2013)
 - Pourquoi compresser ?
- Pourquoi compresser ?
Comme nous venons de le voir, un signal vidéo représente 1 485 000 000 informations basiques par seconde. C’est considérable. Pour échanger des images, il faut donc, soit disposer d’une bande passante de 1, 485 GHz pour être en temps réel, soit faire abstraction du temps réel et travailler en bande passante restreinte, mais alors les temps de transfert deviennent prohibitifs.
Indépendamment de la livraison et du transport, comment enregistrer un signal représentant un tel débit ? Les machines capables de gérer un tel flux sont extrêmement coûteuses. Enfin, comment transmettre en vue d’une diffusion chez l’utilisateur un tel flux ?
Il y a donc plein de bonnes raisons pour diminuer le nombre d’informations et réduire le flux des données, en autre terme “compresser” le signal et le rendre “plus léger”.
- Qu’est ce que la compression ?
Un signal numérique est constitué d’une suite de “0” & de “1”, en l’occurrence 1 485 000 000 informations binaires par seconde pour un signal vidéo HD. La compression consiste à réduire le nombre de données tout en essayant de se rapprocher le plus possible de l’original lors de la reconstruction du signal.
La compression est rendue possible par le fait que la vidéo est aujourd’hui digitale. A l’époque de l’analogique, c’était impensable.
Pour comprendre comment fonctionne la compression, il faut s’interroger sur le contenu d’une image. Dans une image, il arrive fréquemment que 2 points voisins, voire plus, soient identiques. Dans ces conditions, quel est l’intérêt de transmettre chacun des pixels identiques, il est plus simple de dire : 6 pixels qui se suivent sont de telle couleur. On a gagné des données. On a réduit le nombre d’informations sans pour autant compromettre le contenu intrinsèque de l’image. On a apporté une compression. Ce type de compression utilise la redondance d’informations du contenu de l’image (spatial redundancy) c’est la redondance spatiale.
Le majeur problème de la compression réside dans le fait qu’il n’est pas aisé de décider, arbitrairement, quel pixel est sensible et quel autre ne l’est pas et peut être négligé. Il faut donc, au moyen d’un artifice quelconque, transformer l’image en grandeurs mathématiques afin d’apporter des calculs de redondance, de prédiction, etc.
Découpage en blocs
C’est le préalable à tout travail de compression.
La majorité des algorithmes de compression, qui ne sont pas sans perte (losless), découpe l'image en blocs carrés fixes de 256 pixels (16x16) ou de 64 pixels (8x8), c’est le cas du MPEG2, et du JPEG.
En fait, tout découle du JPEG. Il y a eu le MJPEG puis le MPEG ;

![]() La transformée en DCT est à l’origine de la compression JPEG et représente encore aujourd’hui le principe de compression le plus utilisé. Pour rester généraliste, on peut dire que c’est une opération mathématique qui permet de transposer le domaine d'étude, tout en conservant la fonction étudiée.
La transformée en DCT est à l’origine de la compression JPEG et représente encore aujourd’hui le principe de compression le plus utilisé. Pour rester généraliste, on peut dire que c’est une opération mathématique qui permet de transposer le domaine d'étude, tout en conservant la fonction étudiée.
Quand on étudie une image, on a affaire a une fonction spatiale à 3 facteurs : X et Y, qui localisent le pixel dans l’image, et le facteur Z qui fournit la valeur du pixel. En RGB, on multiplie par 3 les informations, puisque chacune des composantes de couleur donne une valeur à chaque pixel.
La transformée DCT est une opération voisine de la transformée de Fourier, à la différence prêt que l’on décompose suivant le cosinus au lieu du sinus. La transformée de Fourier tout le monde connaît. On apprend ça à l’école.
Toute forme d’onde ou signal complexe peut être décomposé en une somme de signaux périodiques simples.
On transforme donc une courbe analogique complexe en une multitude de fréquences, ce qui correspond à transposer une courbe analogue dans un domaine fréquentiel.
Une fois dans le domaine fréquentiel, on va pouvoir faire subir de nombreuses opérations mathématiques à notre signal.
Exemple d’un signal carré
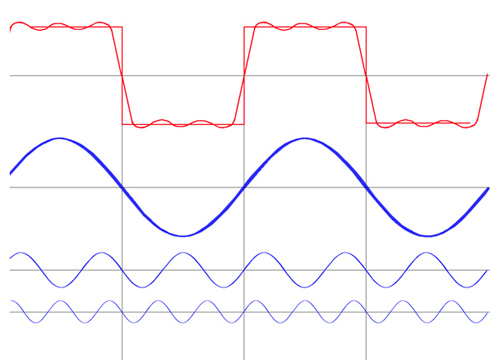
Avec 3 sinusoïdes, de rang impair, combinées entre elles, on obtient un signal carré…
enfin presque…
Il faudrait rajouter quelques harmoniques pour obtenir un carré bien défini.
Dans le cas présent les fréquences sont :
Fondamental harmoniques 3 & 5
Si l’exemple du carré peut paraitre banal, cette méthode a l’avantage de s’appliquer à n’importe quel signal analogique, ce qui permet de prendre une forme d’onde quelconque et de la transposer dans le domaine mathématique.
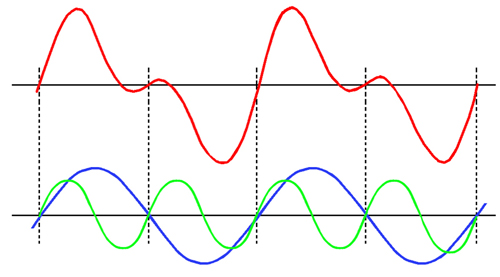
Ici, un exemple avec une fondamentale et un harmonique 2
La transformée DCT (Discrete Cosine Transform), est une technique numérique qui permet de remplacer des données de l’image par transformation de l'information du domaine spatial de l'image en une représentation dans le domaine fréquentiel.
On transforme les pixels en valeur de coefficients liés à la fréquence d’analyse de la zone. Le coefficient le plus élevé correspond à la zone où les pixels changent le plus rapidement d’état (luminance et chrominance) alors que les coefficients les plus faibles sont le reflet des zones qui changent le moins fréquemment.
Les basses fréquences se trouvent en haut à gauche de la matrice, et les hautes fréquences en bas à droite.
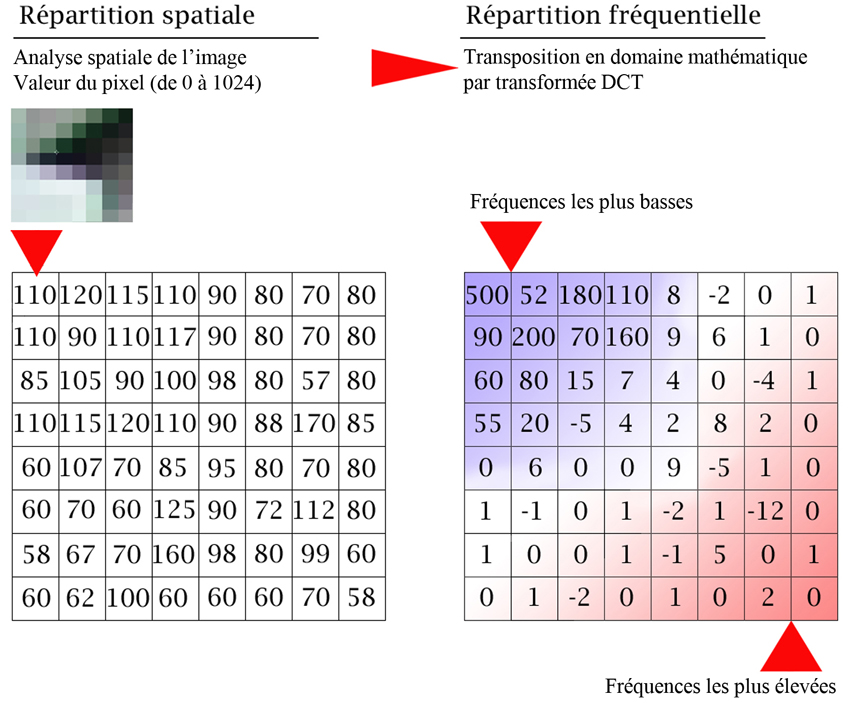
![]() Le fait de changer de domaine est intéressant à plus d’un titre car une image fournit une continuité d’informations de valeurs relatives aux pixels qu’il est difficile de trier ou d’éliminer sans risque. D’où une grande complexité à réduire le volume des informations.
Le fait de changer de domaine est intéressant à plus d’un titre car une image fournit une continuité d’informations de valeurs relatives aux pixels qu’il est difficile de trier ou d’éliminer sans risque. D’où une grande complexité à réduire le volume des informations.
La transformée DCT s'applique à une matrice carrée, généralement de 64 valeurs (8 x 8) et son résultat est représenté dans une matrice de même dimension.
A ce stade, on n’a pas gagné en quantité d’informations puisqu’on remplace une table de 64 valeurs par une autre table identique de 64 valeurs.
En revanche, avec la transformée en DCT, on décrit la totalité des informations de l'image par un ensemble de coefficients, relatifs aux fréquences, dans un domaine mathématique.
Il ressort de nombreuses études que la partie sensible d’une image est représentée en gros par 25% des informations qui correspondent aux coefficients les plus faibles, les basses fréquences, la partie “lente” de l’image transformée, qui a une grande importance pour l’œil.
L’œil est peu sensible aux changements rapides d'intensité du pixel, représentés par les hautes fréquences de la transformée qui peuvent être considérées comme non significatives au niveau de la description du contenu de l’image
Cela signifie donc que les pixels variant rapidement d’un instant à l’autre et correspondant aux hautes fréquences de la matrice, n’étant pas significatifs, peuvent être simplement négligés.
Il est temps de gagner de la place et d’appliquer différents traitements à notre table de coefficients.
Si on décide de mettre à 0 les quelques 75 % des coefficients les plus élevés, qui ne seraient pas significatifs, on obtient une sacrée réduction de données.
Plus généralement, en ne retenant principalement que les coefficients correspondants aux fréquences basses et en négligeant volontairement les hautes fréquences, par application d’une table de quantification ou d’un seuil, nous allons pouvoir réduire le volume des données de manière appréciable.
Dernière étape, le codage de l’information.
On a réduit la quantité d’information, mais encore faut-il savoir en tirer partie. Les valeurs de la table vont être codées, par une méthode mathématique, codage RLE, de Huffman, codage entropique, ou autre…
Comme on le voit dans la précédente figure, les 51 valeurs 0 qui se suivent ne vont prendre qu’une très petite place si l’on décide de les coder sous une forme du type : 51 x 0.
La transformée en DCT s'accompagne d'une méthode d'inversion pour pouvoir revenir dans le domaine spatial de l’image lors de la reconstruction.
En résumé, après avoir codé l’image en donnée fréquentielles, on élimine les fréquences dont l’incidence est minime sur la perception visuelle, tout en permettant par processus inverse de retrouver le domaine spatial de l’image et le retour à une représentation en pixels.
Voilà en gros comment ça marche, mais il y a d’autres procédés.
Pour le moment, nous sommes restés dans le domaine spatial de la seule trame à analyser, la redondance spatiale de l’image. On sait très bien que le facteur temps aussi peut permettre d’économiser des données car d’une trame à l’autre toute l’image ne change pas, une partie du contenu de l’image est conservée.
Pourquoi ne pas regarder, dans le temps, les trames de devant ainsi que celles de derrière pour voir ce qui est commun ?
Quand on trouve des données similaires, il suffit de dire : Comme trame XX, avec éventuellement un déplacement codé en vecteur.
Dans ces conditions, on ne transcrit plus le contenu lui-même. Ce procédé de redondance temporelle (Temporal redundancy) repose sur la redondance dans le temps du contenu des images.
Une combinaison des deux procédés, redondance spatiale et redondance temporelle, permet d’obtenir des techniques efficaces de compression.
Il ne reste plus qu’à appliquer des règles de calcul pour réduire la quantité de bits nécessaire à décrire les informations conservées et on a créé un codeur !
Ce qu’il faut retenir :
- La redondance spatiale intervient sur une seule trame.
- La redondance temporelle intervient sur un ensemble de trames.
Donc, si l’on intervient sur plusieurs trames, il y a fort à parier que ce ne sera pas très pratique à utiliser en montage. Et c’est le cas.
Pour le montage, on préfèrera les codecs Intra Frame qui décrivent intégralement le contenu de l’image en propre sans relation avec le contenu des images adjacentes.
 A partir des techniques disponibles on peut apporter des variations à l’infini et fabriquer nombre de Codec’s. C’est bien entendu ce qui s’est réellement passé.
A partir des techniques disponibles on peut apporter des variations à l’infini et fabriquer nombre de Codec’s. C’est bien entendu ce qui s’est réellement passé.
D’un certain coté c’est relativement légitime car les besoins ne sont pas les mêmes suivant la phase de travail.
- Captation >> Enregistrement du signal
- Post production >> Montage >> Trucage & Effets spéciaux.
- Transport >> Livraison du signal >> Contribution
- Diffusion >> à l’utilisateur final
- Nature du signal vidéo et variation au cours de la chaîne de travail
On n’a pas les mêmes besoins suivants les diverses étapes de la chaîne de travail.

Bien entendu chacune de ces étapes est compartimentée en différentes sous-étapes.
En matière de captation, il nous faut des codecs susceptibles de travailler Une fois. On n’a pas vocation à reconditionner le signal dans son environnement de tournage par la suite.
En Montage, il nous faut de codecs qui ne détériorent pas l’image et se montent facilement, on s’orientera plutôt vers des codec’s de type I Frame qui permettent de monter à l’image près.
Quand à la diffusion, le but est de prendre le moins de place possible. On est de toute manière en bout de chaîne et on n’a pas besoin de restaurer le signal.
On peut donc avoir recours à une compression massive et destructrice sans “gros” problème, c’est bien d’ailleurs ce qui se passe dans la vie de tous les jours !
Le tout n’est pas de définir arbitrairement un flux dans son coin, il faut bien entendu tenir compte des “tuyaux” qui sont utilisés.
Le bon vieux Hertzien analogue est définitivement en bout de vie.
La TNT – Télévision Numérique Terrestre (Hertzienne) utilise des canaux de l’ordre de 6 MHz, par chaîne, qui n’ont pas augmentés, que l’on soit en SD ou en HD !
A ne pas perdre de vue : Pour relire un fichier encodé il faut impérativement :
- Disposer du bon lecteur de conteneur
- Disposer du bon codec à l’intérieur même de ce conteneur.
On peut donc trouver des machines, capables de lire du Quick Time .mov mais ça ne veut pas dire qu’elles seront capables de lire tous les fichiers QT !
 Intra Frame & Inter Frame :
Intra Frame & Inter Frame :
Il existe donc deux procédés majeurs de compression qui diffèrent par le nombre de trames utilisées lors de la description de l’image :
Le procédé intra-trame et le procédé inter-trame.
Le procédé intra-trame (travaillant sur la redondance spatiale de l’image) décrit tout le contenu de l'image et permet donc aisément de faire du montage.
En revanche, le procédé inter-trame (travaillant sur la redondance temporelle des images) décrit le contenu de l’image active à partir de données provenant d’autres images. On conçoit aisément que le montage va devenir compliqué suivant la séquence d’images mises en œuvre.
Le procédé inter-trame travaille sur 3 types d’images :
- I - Les images I (Intra frame) considérées comme images de référence.
- P - Les images P (Previous/Predicted) qui sont calculées à partir de l’image précédente
- B - Les images B (Bidirectionnal/Predicted) qui sont calculées à partir de l’image précédente ou de l’image suivante et des deux à la fois.
Une séquence d’image Inter Frame se présentera donc comme une suite d’images dépendantes jusqu’à la prochaine image de référence - I - :
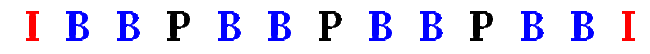
Avec un gop de 12, ce qui est une valeur courante, une image I, image Intra-frame de référence, est insérée toutes les 12 frames.
Comme il en faut pour tous les gouts, on va pouvoir choisir le codec le mieux adapté à son application.
En effet, un codec de diffusion n’a pas la même tâche à remplir qu’un codec de prise de vue ou de montage.
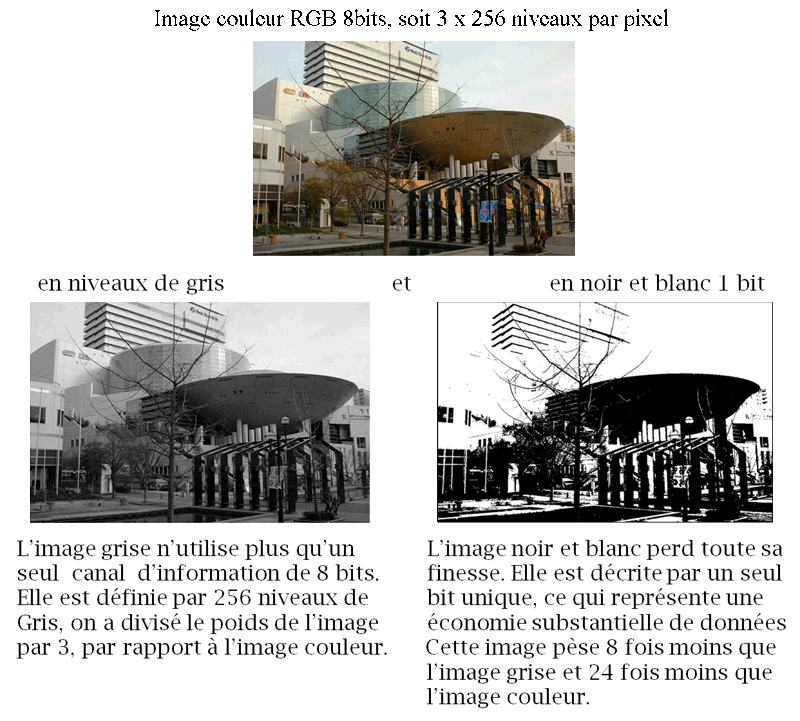
 Résolution de la couleur :
Résolution de la couleur :
L’image de référence est une image couleur RGB 8 bits.
Mais attention, il faut être prudent, certaines méthodes peuvent "agresser" l'image alors que d'autres auraient tendance à être plus accomodantes.
Il faut donc choisir le bon codec en fonction de l'utilisation et du rapport Compression/Qualité d'image dont on a besoin.
Sous-échantillonnage des couleurs
Il est bien connu que l’œil n’est pas très précis en matière de chroma, ce qui permet d’échantillonner les signaux vidéo en 4 : 2 : 2 . Dans les codec’s, on remet une couche en quelque sorte et on profite de ce manque de sensibilité de l’œil pour réduire la quantité d’information par sous-échantillonnage des signaux de chrominance. Ce sous-échantillonnage permet facilement de réduire par 2 la quantité des données.
La résolution ou taille de l’image :
Une méthode aisée de réduction du nombre des informations et donc de compression des données consiste à diminuer la dimension de l’image.
C’est simple et efficace. Pour un simple visionnage, on n’a pas besoin d’une pleine résolution, le fait de réduire les proportions de l’image fait gagner un nombre important d’informations : 320 x 240 >>> 1920 x 1080
L’image en pleine résolution HD est 27 fois plus encombrante !
Le flux ou le débit :
Un flux non compressé SD correspond à 270 MB/s et un flux HD SDI non compressé correspond à 1, 485 GB/s.
Par l’intermédiaire de calculs et d’algorithmes spécifiques, on peut baisser le débit dans des proportions importantes qui dépendent, en grande partie, du traitement de la réduction des données qui a été appliqué à l’image.
Appliquer une réduction du débit d'un signal HD par 10 permet d’obtenir un flux de l’ordre de 145 MB/s, qui est comparable à un flux SD avec un taux de compression "losless" de l'ordre de 2, c’est le cas de figure du HD CAM (qui utilise en fait la partie enregistrement du Digital Betacam à quelques modifications près)
Le DIGITAL BETACAM compresse en gros le signal SD par 2 avec un algorithme Sony Propriétaire.
Le HD CAM, en compressant en gros par 10, permet d’enregistrer un signal HD avec une bande passante de l’ordre de 150 MB/s. (ce qui correspond aux capacités d'un enregistreur Digital BETACAM)
La fréquence image :
On n’a pas toujours besoin de disposer de la cadence fluide de 25 Images/s. Une cadence à 12,5 Images/s permet de diviser par 2 le nombre des données.
Quantification :
On peut intervenir sur la quantification. Le signal de départ était en 10 Bits, le fait de le ramener à 8 Bits permet de réduire les informations par un facteur de 20 %.
Bref, tout est bon pour économiser des données
C’est la vocation des codeurs de faire feu de tout bois pour réduire la quantité des informations.
L’encapsulation :
Un flux d’information est fourni avec un codage donné dans un conteneur donné.
Le Quick Time d’Apple, caractérisé par une extension .mov, est un conteneur qui permet de délivrer des informations sous une grande variété de codec’s.
On peut trouver du codage DV en .mov. On peut également trouver du H/ 264 en .mov, ou bien de l’Apple Pro Res 4 2 2, etc.
Débit constant ou variable :
Pour revenir sur le “bit rate”, débit en français, nous disposons de plusieurs choix afin d’affiner les paramètres applicables à la compression désirée.
- CBR - flux constant : Constant Bit Rate
- VBR - flux variable : Variable Bit Rate
Le flux constant, c’est simple, on travaille tous les contenus d’images de manière identique avec une “fréquence donnée”.
En règle générale, le flux variable apporte une meilleure précision ou résolution d’image en permettant au codec de mieux surmonter les séquences complexes.
Quand les choses sont simples on travaille à débit modéré et quand les choses deviennent complexes, on accélère et on met tous ses efforts afin de décrire au mieux le signal. On n’hésite pas à augmenter la bande passante. Tout ceci dans des limites programmables :
- Débit moyen
- Débit Pic
Le mode VBR, offre également un choix en matière de “passes” :
- Simple passe
- Multi passes
Le multi passes étant en général accompagné de la pudique mention :
Prend plus de temps !
Sauf si le temps est un facteur capital, on a toujours intérêt à souscrire à l’option multi passes car le résultat est grandement amélioré par rapport à la passe unique.
En mode 2 passes, le codec va, dans un premier temps, “regarder” le sujet et noter toutes les complexités et difficultés liées au contenu de l’image. Puis, en deuxième passe, il mettra en pratique son apprentissage précédent et utilisera ses ressources intelligemment en connaissance de cause, d’où un résultat bien meilleur et une bonne adéquation entre compression et contenu de l’image.
- MPEG 2 / MPEG 4
MPEG signifie Motion Picture Expert Group.
C’est donc à l’origine un groupe de travail qui s’est penché sur la façon de réduire les données associées à des images animées.
Ce groupe d’expert a définit des spécifications et créé des familles d’outils.
Il n’est donc pas étonnant que tous les MPEG ne se valent pas !
Comme dans tous les systèmes de codage et à commencer par le DCT qui est tout de même à l’origine de ces technologies, on découpe l’image en “macro blocks”.
D’où le désagréable effet de mosaïque quand quelque chose ne va pas.
L’une des différences notables entre le MPEG 2 et le MPEG 4 réside dans la description des macros blocks. En MPEG 2 les Blocks sont d’une dimension de 16 x 16 ou, au plus petit, de 8 x 8, alors qu’en MPEG 4, les Blocks sont fixés une fois pour toute à 16 x 16 mais sont subdivisés en “sous blocks” allant jusqu’à 4 x 4.
 Il existe des méthodes objectives et des méthodes subjectives pour vérifier de la qualité et de l’efficacité d’un Codec. Si l’on ne s’était reposé que sur des méthodes objectives, les Codec’s n’en seraient certainement pas au stade où ils en sont aujourd’hui. Des études subjectives, sur “échantillonnage de population”, ont accompagné le développement des codecs.
Il existe des méthodes objectives et des méthodes subjectives pour vérifier de la qualité et de l’efficacité d’un Codec. Si l’on ne s’était reposé que sur des méthodes objectives, les Codec’s n’en seraient certainement pas au stade où ils en sont aujourd’hui. Des études subjectives, sur “échantillonnage de population”, ont accompagné le développement des codecs.
On présentait des images de référence puis des images compressées. C’est ainsi que l’on a constaté qu’un certain nombre de défauts et artéfacts pouvaient être considérés comme tolérables ou peu gênants.

Analyse objective :
L’analyse objective est facile à mettre en œuvre. On prend d’une part le signal original auquel on ajoute le signal compressé inversé.
Si les deux images sont identiques… il n’y a rien à voir.
En revanche, si les images diffèrent, on peut aller d’un simple ciel peu étoilé à un véritable bas relief suivant la qualité du codage.
Voilà un aperçu de certaines possibilités de réduction de données, donc de compression, en ne tenant compte que de quelques paramètres.
Dans notre précédent exposé, nous n’avons passé en revue que certains paramètres parmi les plus courants. Bien d’autres informations sont à renseigner, en voici un aperçu partiel, toujours non exhaustif...
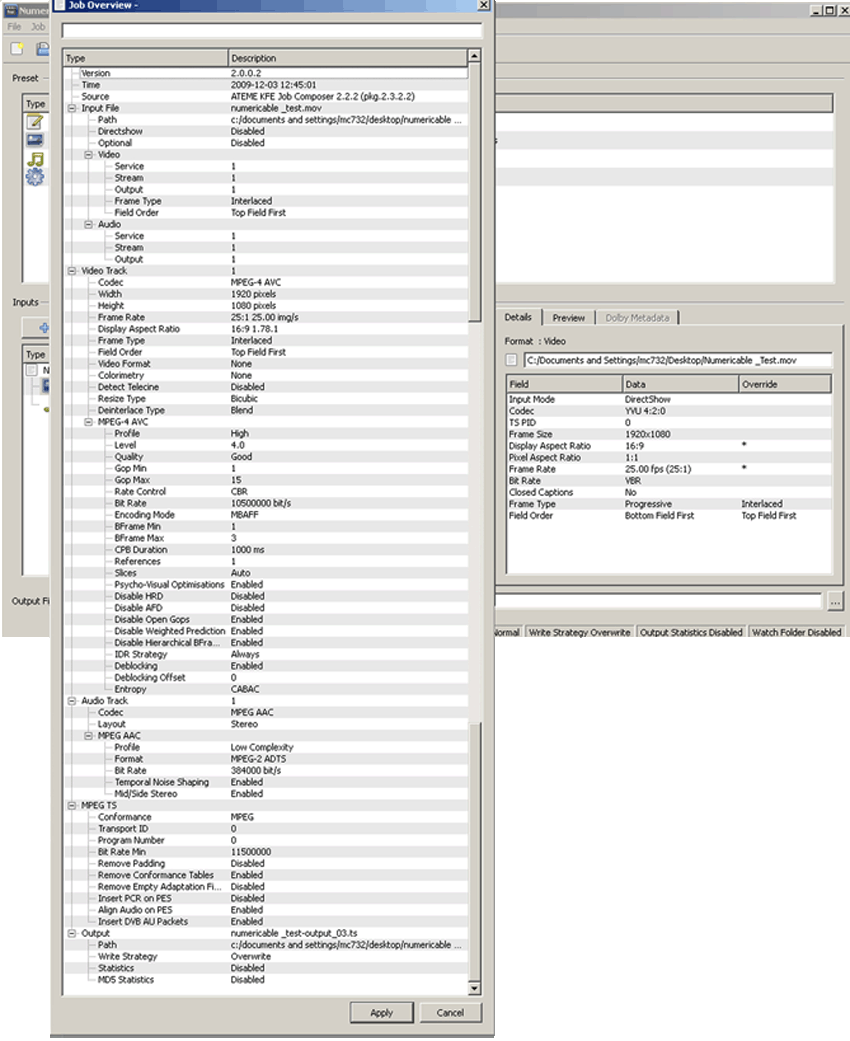
En fait, ce n’est pas si simple !
 Depuis tout le temps ?
Depuis tout le temps ?
Non, pas tout à fait. Il a d’abord fallu disposer de calculateur susceptible de traiter des images pour que l’on commence à s’intéresser au phénomène de la compression.
On peut dater l’origine réelle des travaux de compression d’image à 1978 avec le coup d’envoi du codage JPEG à l’initiative d’un comité d’experts : Joint Photographic Experts Group.
Le JPEG n’est utilisable que pour des images fixes.
Quelques temps après, le MJPEG, entendez Motion JPEG, a permis de compresser et d’enregistrer des flux vidéo sur support informatique en codant individuellement chacune des images en JPEG. C’est donc un mode I Frame, ou Intra Frame, facile à travailler puisque chaque image dispose de sa propre description, sans nécessité de faire appel à d’autres images. A contrario, le débit et le volume des données restent relativement élevés.
Aujourd’hui, on peut considérer que le MJPEG est complètement dépassé, tout en sachant que certain caméscope grand public utilisent toujours des déclinaisons de ce principe de codage vieux de plus de 20 ans.
Le miniDV, par exemple, compresse les images en MJPEG avec un débit de 25 Mbits/s alors que le HDV, lui, compresse en MPEG 2 Long Gop au même débit de 25 MB/s.
Le groupe MPEG a été établi en 1988, soit 10 ans après, dans le but de développer des standards internationaux de compression, décompression, traitement et codage d'images animées.
Tous les MPEG reposent sur le principe de transformée DCT, puis apportent des déclinaisons spécifiques.
A coté du DCT…
Eh bien oui, il existe d’autres procédés.
Il y a donc la quantification vectorielle du CINEPAK, et aujourd’hui, on parle beaucoup d’un codec radicalement différent, d’une bonne qualité et d’une grande efficacité, il s’agit des Ondelettes en français et de Wavelet pour le reste du monde.
Le JPEG 2000 du cinéma numérique repose sur ce principe de même que le DIRAC développé par la BBC.
Le CINEPAK est un codec qui date de 1991 qui a été intégré à Quick Time en 1992, puis à Microsoft Windows en 1993. A l’époque on encodait une résolution de 320 x 240 avec un débit de l’ordre de 150 KO/s, ce qui était compatible avec la lecture de CD ROM.
Dans la foulée, INTEL développe son Codec Indeo et Sorenson Vidéo sort également des outils de compression.
Le CINEPAK travaille sur une quantification vectorielle qui est un algorithme très différent du DCT. Cet algorithme avait le mérite de demander peu de ressource processeur et de se satisfaire de CPU lent. A l’époque le processeur Motorola 68030 était cadencé à 25 MHz.
Le CINEPAK opère un codage Intra Frame avec des images clefs. Il divise chaque image en bande horizontale se référant à une palette incluse dans les images clefs. Chaque bande est ensuite subdivisée en carré de 4 x 4 et analysé.
Le fait de travailler en vecteur offre de nombreuses possibilités de transformation car nous sommes également dans un monde mathématique. La redondance temporelle du codage MPEG fait appel au vectoriel. Au lieu d’enregistrer des portions d’image, on enregistre simplement les vecteurs qui transposent les parties communes de l’image d’une trame à une autre.
Etre dans un domaine mathématique permet aisément de faire subir aux vecteurs des calculs divers et variés reposant sur des algorithmes maitrisés. L’un des grands avantages des vecteurs est d’être une grandeur mathématique facile à “triturer et à manipuler”.
On peut en avoir l’illustration en comparant des polices vectorielles et des polices bitmaps, ces dernières étant des polices “pixellisées”.

C’est toute la différence entre le domaine de l’image, dans lequel on gère des pixels, et le domaine mathématique, dans lequel on traite des vecteurs qui sont autrement plus faciles à manipuler et permettent de conserver la qualité en fonction de la taille.
- Artéfacts & taux de compression.
L’image qui suit présente une partie des principaux artefacts dus à la compression.
On peut comparer l’image de base, en pleine résolution, aux images détériorées qui ont subi une compression.
Dans cet exemple, nous avons appliqué 3 taux de compression différent et n’avons pas exagéré le défaut pour le rendre plus évident, ce n’était pas nécessaire.
Pour mettre en évidence la dégradation, nous avons opté pour l’analyse d’une portion de l’image grossie.
On constate que l’image est plus dégradée lorsque le taux de compression augmente, ce qui n’a rien d’étonnant.
Seuls les codecs “Lossless” peuvent prétendre ne pas dégrader et permettre une reconstruction quasi parfaite du signal.
Malheureusement il n’y a pas de secret, si l’on souhaite compresser au-delà d’un taux de 2, il faut faire appel à des codecs destructeurs et les défauts deviennent irréversibles.
- Défauts et artéfacts de la compression.

Voilà, j'espère que maintenant vous en savez un peu plus sur le monde des codeurs/décodeurs.
bg-10/2013


